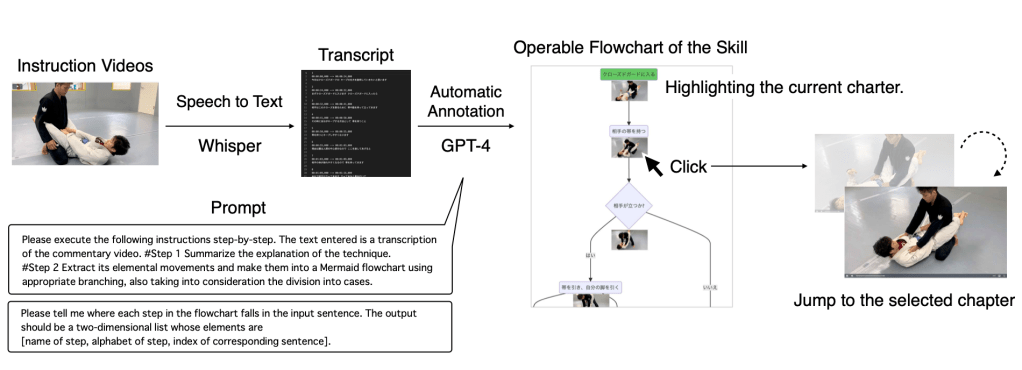
The use of video for learning physical skills such as modern martial arts is becoming popular. Physical skills such as modern martial arts require decisions depending on the situation. An example of these decisions is selecting an appropriate off-balance technique based on the position of the opponent’s feet. However, the existing interface does not support video browsing based on the structure of the physical skills, including situations and the decisions that should be made at that time. We hypothesize browsing based on the structure can help the user’s skill comprehension. In this paper, we propose a structure-based video browsing method, SkillsInterpreter, which automatically generates a flowchart of the speech-contained skill instruction video by large language models (LLMs). The generated flowchart explores desired scenes, checks the current chapter, and reviews the skill structure while watching the video. Our study included interviews with experts and evaluations with learners in modern martial arts. Based on our two studies, it was suggested that SkillsInterpreter can support video-based skill learning in modern martial arts, especially in Brazilian Jiu-Jitsu, which needs situation- specific decision making.
現代格闘技のような身体的技能の学習において、ビデオの使用が人気を博している。身体的技能は、状況に応じた判断を要求される。例えば、相手の足の位置に基づいて適切な崩しの技を選択するなどがある。しかし、既存のインターフェースは、状況やその時に行うべき判断を含む身体的技能の構造に基づいたビデオブラウジングをサポートしていない。本研究では、構造に基づいたブラウジングがユーザーの技能理解を助けると仮定する。この論文では、大規模言語モデル(LLMs)を用いて、スピーチを含む技術指導ビデオからフローチャートを自動生成する構造ベースのビデオブラウジング手法「SkillsInterpreter」を提案する。生成されたフローチャートは、ビデオブラウジング中に求められるシーンを探索し、現在のチャプターを確認し、技の構造を俯瞰することのできる機能をユーザに提供する。当研究は、現代格闘技の専門家と学習者を対象にしたインタビューと評価を行った。2つの評価実験に基づいて、SkillsInterpreterは特にブラジリアン柔術のように状況特有の判断が必要な現代格闘技におけるビデオベースの技能学習を支援できると示唆された。
Publication
Conference Paper 口頭発表 : Kotaro Oomori, Yoshio Ishiguro, and Jun Rekimoto. 2024. SkillsInterpreter: A Case Study of Automatic Annotation of Flowcharts to Support Browsing Instructional Videos in Modern Martial Arts using Large Language Models. In Proceedings of the Augmented Humans International Conference (AHs ’24). ACM, New York, NY, USA, 9 pages. Preprint is here.
