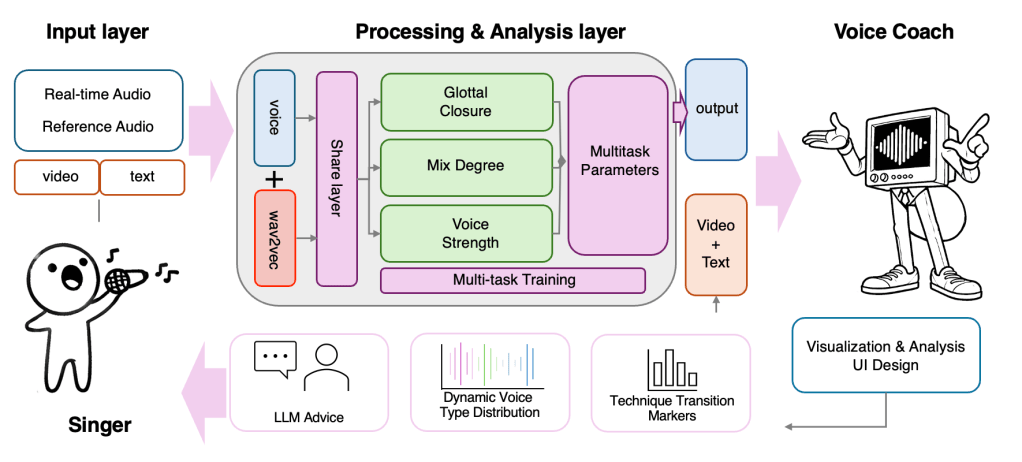
VoiceCoach is a multimodal interactive system that augments vocal learners’ perception, cognition, and motor control when practicing complex techniques such as mixed voice. Learning invisible vocal techniques is challenging because key articulators and resonance changes are internal and cannot be directly observed. VoiceCoach addresses this by implementing an end-to-end augmentation pipeline: a multidimensional vocal technique recognition model estimates key voice-quality parameters from audio, progressive visualizations help learners interpret these parameters as spatial and temporal patterns, and an LLM-powered feedback mechanism translates model outputs into personalized explanations and concrete practice suggestions. In a controlled study with 10 participants, VoiceCoach was associated with a 52.9% reduction in practice time, a 2.38× increase in voice type diversity, and higher mixed-voice reference matching (55.3% → 74%) compared to audio-only practice. We discuss VoiceCoach as a case study of human augmentation for invisible skills, with design implications for multimodal feedback and AI-guided learning systems.
VoiceCoachは、ミックスボイスなどの複雑な発声技術を練習する際に、学習者の知覚・認知・運動制御を拡張するマルチモーダルなインタラクティブシステムです。発声における重要な調音器官や共鳴の変化は内部で起こるため直接観察できず、独学での習得は非常に困難です。VoiceCoachはこの課題に対し、エンドツーエンドの拡張パイプラインを実装しています。多次元的な発声技術認識モデルが音声から声質パラメータを推定し、段階的なビジュアライゼーションがそのパラメータを空間的・時間的なパターンとして提示し、LLMを用いたフィードバック機構がモデル出力を個別の説明と具体的な練習提案に変換します。10名を対象とした対照実験では、音声のみの練習と比較して、練習時間の52.9%短縮、声種の多様性2.38倍増加、ミックスボイス参照一致率の向上(55.3% → 74%)が確認されました。本研究は「見えないスキル」の人間拡張システムの事例として、マルチモーダルフィードバックおよびAIを活用した学習システムの設計指針を示します。
Publications
- Yaolin Zheng and Yoshio Ishiguro. 2026. VoiceCoach: An Augmented Human System for Learning Invisible Vocal Techniques. In The Augmented Humans International Conference 2026 (AHs 2026), March 16–19, 2026, Okinawa, Japan. ACM. https://doi.org/10.1145/3795011.3795040
