
D1の西田がACM UIST 2024にてReal-Time Word-Level Temporal Segmentation in Streaming Speech Recognitionというタイトルでデモ発表をします.
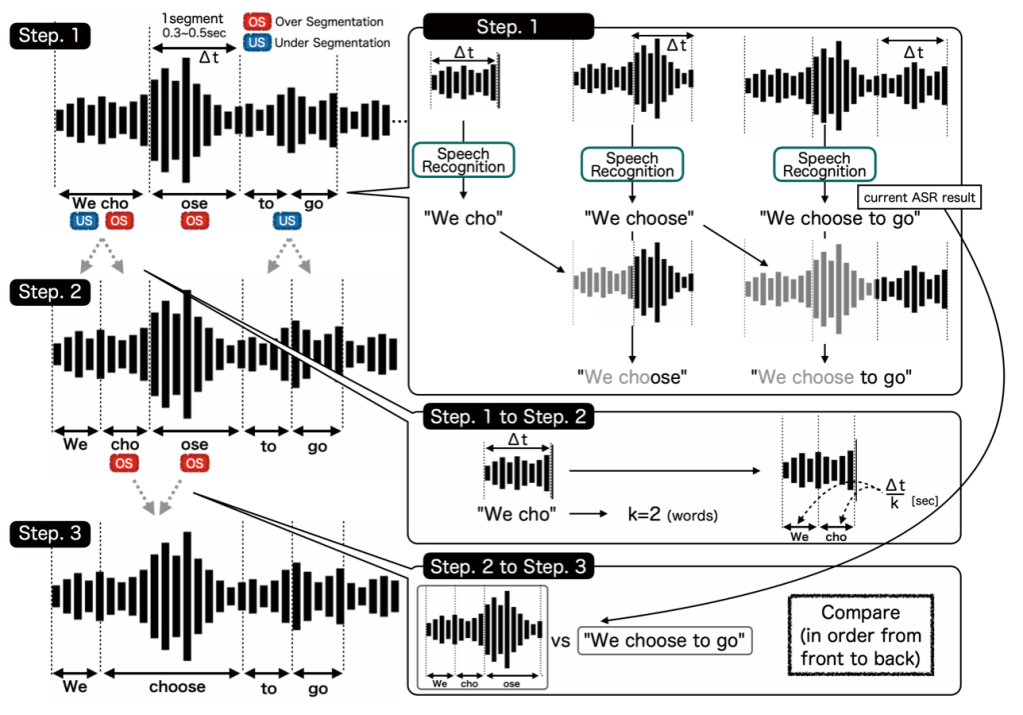
この研究は同時音声認識中における単語単位のアライメント(音声データの中で特定の時間区間がどの単語に対応しているか)手法について論じています.この技術が充分に発展すれば健常者と難聴者間のリアルタイムの会話において字幕に健常者話者の音声的特徴(声の大きさなど)を反映させることにつながります.
Naoto Nishida, Hirotaka Hiraki, Jun Rekimoto, Yoshio Ishiguro.
Real-Time Word-Level Temporal Segmentation in Streaming Speech Recognition.
37th Annual ACM Symposium on User Interface Software and Technology (UIST 2024), October 2024. 3 pages. DOI:10.1145/3672539.3686738.

プロジェクトページ: https://ishiguro-lab.org/projects/assistive-subtitles/

コメントを残す